
Note
Go to the end to download the full example code.
DTT performance benchmarks#
This example benchmarks the DTT performance for the different algorithms available in Shamrock
9 import random
10 import time
11
12 import matplotlib.colors as colors
13 import matplotlib.pyplot as plt
14 import numpy as np
15
16 import shamrock
17
18 # If we use the shamrock executable to run this script instead of the python interpreter,
19 # we should not initialize the system as the shamrock executable needs to handle specific MPI logic
20 if not shamrock.sys.is_initialized():
21 shamrock.change_loglevel(1)
22 shamrock.sys.init("0:0")
Use shamrock documentation style for matplotlib
28 shamrock.matplotlib.set_shamrock_mpl_style()
Main benchmark functions
33 bounding_box = shamrock.math.AABB_f64_3((0.0, 0.0, 0.0), (1.0, 1.0, 1.0))
34
35
36 def benchmark_dtt_core(N, theta_crit, compression_level, ordered_result, nb_repeat=10):
37 times = []
38 random.seed(111)
39 max_mem_delta = 0
40 for i in range(nb_repeat):
41 positions = shamrock.algs.mock_buffer_f64_3(
42 random.randint(0, 1000000), N, bounding_box.lower, bounding_box.upper
43 )
44 tree = shamrock.tree.CLBVH_u64_f64_3()
45 tree.rebuild_from_positions(positions, bounding_box, compression_level)
46 shamrock.backends.reset_mem_info_max()
47 mem_info_before = shamrock.backends.get_mem_perf_info()
48 times.append(
49 shamrock.tree.benchmark_clbvh_dual_tree_traversal(tree, theta_crit, ordered_result)
50 * 1000
51 )
52 mem_info_after = shamrock.backends.get_mem_perf_info()
53
54 mem_delta = (
55 mem_info_after.max_allocated_byte_device - mem_info_before.max_allocated_byte_device
56 )
57 max_mem_delta = max(max_mem_delta, mem_delta)
58 return times, max_mem_delta
59
60
61 def benchmark_dtt(N, theta_crit, compression_level, ordered_result, nb_repeat=10):
62 times, max_mem_delta = benchmark_dtt_core(
63 N, theta_crit, compression_level, ordered_result, nb_repeat
64 )
65 return min(times), max(times), sum(times) / nb_repeat, max_mem_delta
Run the performance test for all parameters
70 def run_performance_sweep(compression_level, threshold_run, ordered_result):
71 # Define parameter ranges
72 # logspace as array
73 particle_counts = np.logspace(2, 7, 10).astype(int).tolist()
74 theta_crits = [0.1, 0.3, 0.5, 0.7, 0.9]
75
76 # Initialize results matrix
77 results_mean = np.zeros((len(theta_crits), len(particle_counts)))
78 results_min = np.zeros((len(theta_crits), len(particle_counts)))
79 results_max = np.zeros((len(theta_crits), len(particle_counts)))
80 results_max_mem_delta = np.zeros((len(theta_crits), len(particle_counts)))
81
82 print(f"Particle counts: {particle_counts}")
83 print(f"Theta_crit values: {theta_crits}")
84 print(f"Compression level: {compression_level}")
85
86 total_runs = len(particle_counts) * len(theta_crits)
87 current_run = 0
88
89 for i, theta_crit in enumerate(theta_crits):
90 exceed_mem = False
91 for j, N in enumerate(particle_counts):
92 current_run += 1
93
94 if exceed_mem:
95 print(
96 f"[{current_run:2d}/{total_runs}] Skipping N={N:5d}, theta_crit={theta_crit:.1f}"
97 )
98 results_mean[i, j] = np.nan
99 results_min[i, j] = np.nan
100 results_max[i, j] = np.nan
101 continue
102
103 print(
104 f"[{current_run:2d}/{total_runs}] Running N={N:5d}, theta_crit={theta_crit:.1f}...",
105 end=" ",
106 )
107
108 start_time = time.time()
109 min_time, max_time, mean_time, max_mem_delta = benchmark_dtt(
110 N, theta_crit, compression_level, ordered_result
111 )
112 elapsed = time.time() - start_time
113
114 results_mean[i, j] = mean_time
115 results_min[i, j] = min_time
116 results_max[i, j] = max_time
117 results_max_mem_delta[i, j] = max_mem_delta
118
119 print(f"mean={mean_time:.3f}ms (took {elapsed:.1f}s)")
120
121 if max_mem_delta > threshold_run:
122 exceed_mem = True
123
124 return (
125 particle_counts,
126 theta_crits,
127 results_mean,
128 results_min,
129 results_max,
130 results_max_mem_delta,
131 )
Create checkerboard plot with execution times and relative performance to reference algorithm
136 def create_checkerboard_plot(
137 particle_counts,
138 theta_crits,
139 results_data,
140 compression_level,
141 algname,
142 max_axis_value,
143 reference_data,
144 results_max_mem_delta,
145 ):
146 """Create checkerboard plot with execution times"""
147
148 fig, ax = plt.subplots(figsize=(12, 8))
149
150 # Calculate relative performance compared to reference algorithm
151 # results_data / reference_data gives the ratio (>1 means slower, <1 means faster)
152 relative_performance = results_data / reference_data
153
154 # Create the heatmap with relative performance values
155 # Create a masked array to handle NaN values (skipped benchmarks) as white
156 masked_relative = np.ma.masked_invalid(relative_performance)
157
158 # Use a diverging colormap: red for better performance (<1), green for worse (>1)
159 # RdYlGn_r (reversed) has green for high values (worse) and red for low values (better)
160 cmap = plt.cm.RdYlGn_r.copy() # Green for >1 (slower), Red for <1 (faster)
161 cmap.set_bad(color="white") # Set NaN values to white
162
163 # Set the color scale limits for relative performance
164 vmin = 0.5
165 vmax = 1.5
166
167 im = ax.imshow(
168 masked_relative, cmap=cmap, aspect="auto", interpolation="nearest", vmin=vmin, vmax=vmax
169 )
170
171 # Set ticks and labels
172 ax.set_xticks(range(len(particle_counts)))
173 ax.set_yticks(range(len(theta_crits)))
174 ax.set_xticklabels([f"{N // 1000}k" if N >= 1000 else str(N) for N in particle_counts])
175 ax.set_yticklabels([f"{theta:.1f}" for theta in theta_crits])
176
177 # Add labels
178 ax.set_xlabel("Particle Count")
179 ax.set_ylabel("Theta Critical")
180 ax.set_title(
181 f"Dual Tree Traversal Performance\n(Colors: Relative to Reference, Text: Absolute Time in ms)\ncompression level = {compression_level} algorithm = {algname}",
182 pad=20,
183 )
184
185 # Add text annotations showing the values
186 for i in range(len(theta_crits)):
187 for j in range(len(particle_counts)):
188 value = results_data[i, j]
189
190 if np.isnan(value):
191 # For skipped benchmarks, show "SKIPPED" in black on white background
192 # ax.text(j, i, 'SKIPPED', ha='center', va='center',
193 # color='black', fontweight='bold', fontsize=8)
194 pass
195 else:
196 perf = relative_performance[i, j]
197 mem_delta = results_max_mem_delta[i, j] / 1e6
198 text_color = "black"
199 ax.text(
200 j,
201 i,
202 f"{value:.2f}ms\n{perf:.2f}\n{mem_delta:.2f}MB",
203 ha="center",
204 va="center",
205 color=text_color,
206 fontweight="bold",
207 fontsize=10,
208 )
209
210 # Add colorbar for relative performance
211 cbar = plt.colorbar(im, ax=ax, shrink=0.8)
212 cbar.set_label("Relative performance (time / reference time)")
213 cbar.ax.tick_params(labelsize=10)
214
215 # Add custom tick labels for better interpretation
216 tick_positions = [0.1, 0.2, 0.5, 1.0, 2.0, 3.0]
217 cbar.set_ticks([pos for pos in tick_positions if vmin <= pos <= vmax])
218
219 # Improve layout
220 plt.tight_layout()
221
222 # Add grid for better readability
223 ax.set_xticks(np.arange(len(particle_counts)) - 0.5, minor=True)
224 ax.set_yticks(np.arange(len(theta_crits)) - 0.5, minor=True)
225 ax.grid(which="minor", color="black", linestyle="-", linewidth=1, alpha=0.3)
226
227 return fig, ax
List current implementation
232 current_impl = shamrock.tree.get_current_impl_clbvh_dual_tree_traversal_impl()
233
234 print(current_impl)
impl_param(impl_name="scan_multipass", params="")
List all implementations available
238 all_default_impls = shamrock.tree.get_default_impl_list_clbvh_dual_tree_traversal()
239
240 print(all_default_impls)
[impl_param(impl_name="reference", params=""), impl_param(impl_name="parallel_select", params=""), impl_param(impl_name="scan_multipass", params="")]
Run the performance benchmarks for all implementations
244 results = {}
245
246
247 for ordered_result in [True, False]:
248 for default_impl in all_default_impls:
249 shamrock.tree.set_impl_clbvh_dual_tree_traversal(
250 default_impl.impl_name, default_impl.params
251 )
252
253 n = default_impl.impl_name + " " + default_impl.params + "ordered=" + str(ordered_result)
254
255 print(f"Running DTT performance benchmarks for {n}...")
256
257 compression_level = 4
258
259 threshold_run = 5e6
260 # Run the performance sweep
261 (
262 particle_counts,
263 theta_crits,
264 results_mean,
265 results_min,
266 results_max,
267 results_max_mem_delta,
268 ) = run_performance_sweep(compression_level, threshold_run, ordered_result)
269
270 results[n] = {
271 "particle_counts": particle_counts,
272 "theta_crits": theta_crits,
273 "results_mean": results_mean,
274 "results_min": results_min,
275 "results_max": results_max,
276 "results_max_mem_delta": results_max_mem_delta,
277 "name": n,
278 }
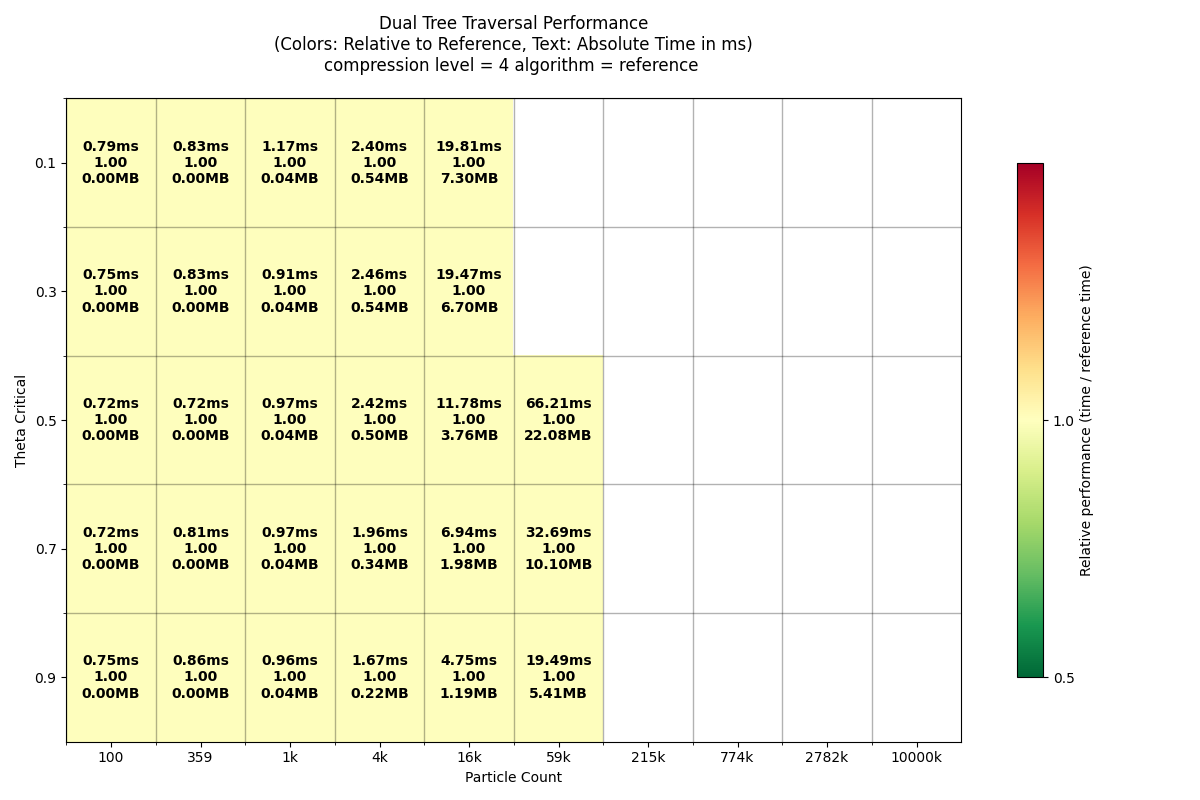
Info: setting dtt implementation to impl : reference [tree][rank=0]
Running DTT performance benchmarks for reference ordered=True...
Particle counts: [100, 359, 1291, 4641, 16681, 59948, 215443, 774263, 2782559, 10000000]
Theta_crit values: [0.1, 0.3, 0.5, 0.7, 0.9]
Compression level: 4
[ 1/50] Running N= 100, theta_crit=0.1... mean=1.954ms (took 0.0s)
[ 2/50] Running N= 359, theta_crit=0.1... mean=1.833ms (took 0.0s)
[ 3/50] Running N= 1291, theta_crit=0.1... mean=2.059ms (took 0.0s)
[ 4/50] Running N= 4641, theta_crit=0.1... mean=4.812ms (took 0.1s)
[ 5/50] Running N=16681, theta_crit=0.1... mean=39.710ms (took 0.5s)
[ 6/50] Skipping N=59948, theta_crit=0.1
[ 7/50] Skipping N=215443, theta_crit=0.1
[ 8/50] Skipping N=774263, theta_crit=0.1
[ 9/50] Skipping N=2782559, theta_crit=0.1
[10/50] Skipping N=10000000, theta_crit=0.1
[11/50] Running N= 100, theta_crit=0.3... mean=1.644ms (took 0.0s)
[12/50] Running N= 359, theta_crit=0.3... mean=1.601ms (took 0.0s)
[13/50] Running N= 1291, theta_crit=0.3... mean=2.038ms (took 0.0s)
[14/50] Running N= 4641, theta_crit=0.3... mean=3.416ms (took 0.1s)
[15/50] Running N=16681, theta_crit=0.3... mean=11.553ms (took 0.2s)
[16/50] Running N=59948, theta_crit=0.3... mean=72.311ms (took 1.0s)
[17/50] Skipping N=215443, theta_crit=0.3
[18/50] Skipping N=774263, theta_crit=0.3
[19/50] Skipping N=2782559, theta_crit=0.3
[20/50] Skipping N=10000000, theta_crit=0.3
[21/50] Running N= 100, theta_crit=0.5... mean=1.563ms (took 0.0s)
[22/50] Running N= 359, theta_crit=0.5... mean=1.914ms (took 0.0s)
[23/50] Running N= 1291, theta_crit=0.5... mean=2.035ms (took 0.0s)
[24/50] Running N= 4641, theta_crit=0.5... mean=2.417ms (took 0.1s)
[25/50] Running N=16681, theta_crit=0.5... mean=5.318ms (took 0.2s)
[26/50] Running N=59948, theta_crit=0.5... mean=16.821ms (took 0.4s)
[27/50] Skipping N=215443, theta_crit=0.5
[28/50] Skipping N=774263, theta_crit=0.5
[29/50] Skipping N=2782559, theta_crit=0.5
[30/50] Skipping N=10000000, theta_crit=0.5
[31/50] Running N= 100, theta_crit=0.7... mean=1.599ms (took 0.0s)
[32/50] Running N= 359, theta_crit=0.7... mean=1.743ms (took 0.0s)
[33/50] Running N= 1291, theta_crit=0.7... mean=1.866ms (took 0.0s)
[34/50] Running N= 4641, theta_crit=0.7... mean=2.128ms (took 0.1s)
[35/50] Running N=16681, theta_crit=0.7... mean=3.377ms (took 0.1s)
[36/50] Running N=59948, theta_crit=0.7... mean=10.360ms (took 0.4s)
[37/50] Running N=215443, theta_crit=0.7... mean=26.543ms (took 1.3s)
[38/50] Skipping N=774263, theta_crit=0.7
[39/50] Skipping N=2782559, theta_crit=0.7
[40/50] Skipping N=10000000, theta_crit=0.7
[41/50] Running N= 100, theta_crit=0.9... mean=1.650ms (took 0.0s)
[42/50] Running N= 359, theta_crit=0.9... mean=1.749ms (took 0.0s)
[43/50] Running N= 1291, theta_crit=0.9... mean=1.850ms (took 0.0s)
[44/50] Running N= 4641, theta_crit=0.9... mean=2.108ms (took 0.1s)
[45/50] Running N=16681, theta_crit=0.9... mean=3.044ms (took 0.1s)
[46/50] Running N=59948, theta_crit=0.9... mean=6.554ms (took 0.4s)
[47/50] Running N=215443, theta_crit=0.9... mean=17.682ms (took 1.2s)
[48/50] Running N=774263, theta_crit=0.9... mean=59.319ms (took 4.4s)
[49/50] Skipping N=2782559, theta_crit=0.9
[50/50] Skipping N=10000000, theta_crit=0.9
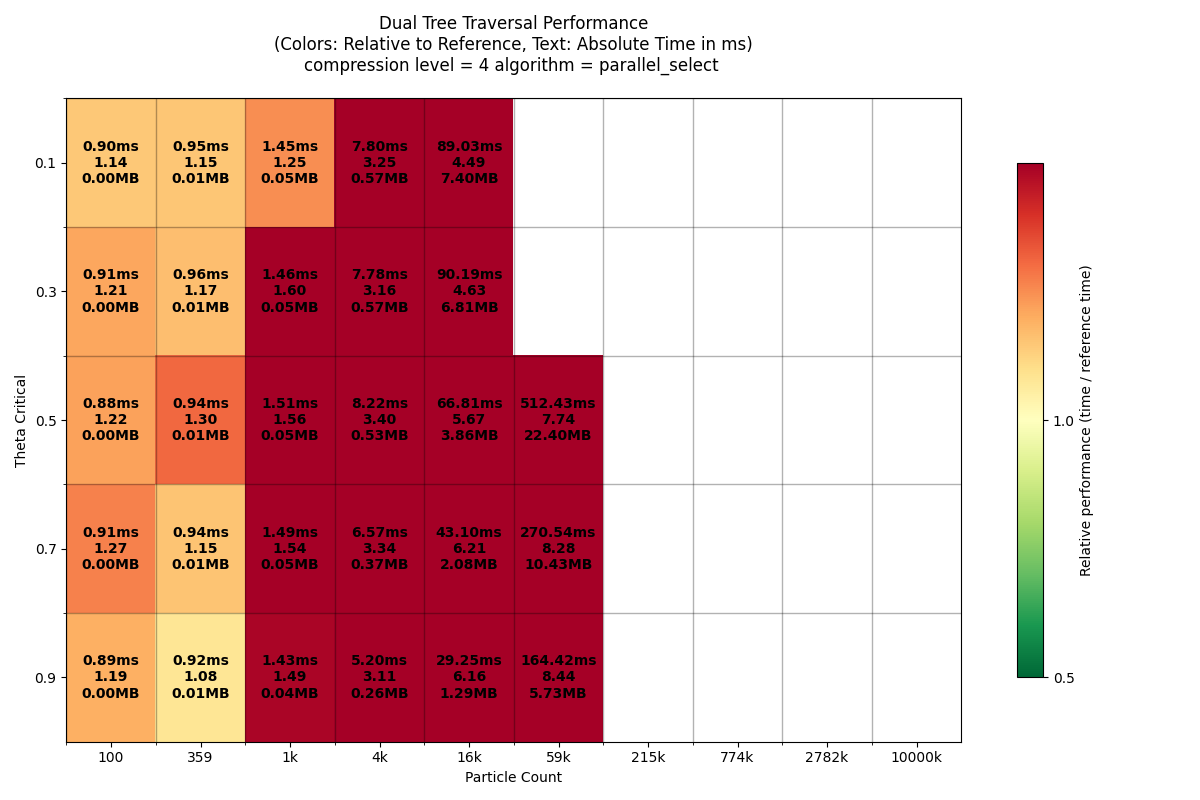
Info: setting dtt implementation to impl : parallel_select [tree][rank=0]
Running DTT performance benchmarks for parallel_select ordered=True...
Particle counts: [100, 359, 1291, 4641, 16681, 59948, 215443, 774263, 2782559, 10000000]
Theta_crit values: [0.1, 0.3, 0.5, 0.7, 0.9]
Compression level: 4
[ 1/50] Running N= 100, theta_crit=0.1... mean=1.403ms (took 0.0s)
[ 2/50] Running N= 359, theta_crit=0.1... mean=1.394ms (took 0.0s)
[ 3/50] Running N= 1291, theta_crit=0.1... mean=1.870ms (took 0.0s)
[ 4/50] Running N= 4641, theta_crit=0.1... mean=7.568ms (took 0.1s)
[ 5/50] Running N=16681, theta_crit=0.1... mean=80.796ms (took 0.9s)
[ 6/50] Skipping N=59948, theta_crit=0.1
[ 7/50] Skipping N=215443, theta_crit=0.1
[ 8/50] Skipping N=774263, theta_crit=0.1
[ 9/50] Skipping N=2782559, theta_crit=0.1
[10/50] Skipping N=10000000, theta_crit=0.1
[11/50] Running N= 100, theta_crit=0.3... mean=0.878ms (took 0.0s)
[12/50] Running N= 359, theta_crit=0.3... mean=0.937ms (took 0.0s)
[13/50] Running N= 1291, theta_crit=0.3... mean=1.433ms (took 0.0s)
[14/50] Running N= 4641, theta_crit=0.3... mean=6.318ms (took 0.1s)
[15/50] Running N=16681, theta_crit=0.3... mean=43.958ms (took 0.5s)
[16/50] Running N=59948, theta_crit=0.3... mean=288.070ms (took 3.2s)
[17/50] Skipping N=215443, theta_crit=0.3
[18/50] Skipping N=774263, theta_crit=0.3
[19/50] Skipping N=2782559, theta_crit=0.3
[20/50] Skipping N=10000000, theta_crit=0.3
[21/50] Running N= 100, theta_crit=0.5... mean=0.874ms (took 0.0s)
[22/50] Running N= 359, theta_crit=0.5... mean=0.960ms (took 0.0s)
[23/50] Running N= 1291, theta_crit=0.5... mean=1.368ms (took 0.0s)
[24/50] Running N= 4641, theta_crit=0.5... mean=3.806ms (took 0.1s)
[25/50] Running N=16681, theta_crit=0.5... mean=17.894ms (took 0.3s)
[26/50] Running N=59948, theta_crit=0.5... mean=92.821ms (took 1.2s)
[27/50] Running N=215443, theta_crit=0.5... mean=413.178ms (took 5.1s)
[28/50] Skipping N=774263, theta_crit=0.5
[29/50] Skipping N=2782559, theta_crit=0.5
[30/50] Skipping N=10000000, theta_crit=0.5
[31/50] Running N= 100, theta_crit=0.7... mean=0.873ms (took 0.0s)
[32/50] Running N= 359, theta_crit=0.7... mean=0.912ms (took 0.0s)
[33/50] Running N= 1291, theta_crit=0.7... mean=1.206ms (took 0.0s)
[34/50] Running N= 4641, theta_crit=0.7... mean=2.700ms (took 0.1s)
[35/50] Running N=16681, theta_crit=0.7... mean=11.305ms (took 0.2s)
[36/50] Running N=59948, theta_crit=0.7... mean=54.116ms (took 0.8s)
[37/50] Running N=215443, theta_crit=0.7... mean=246.255ms (took 3.5s)
[38/50] Skipping N=774263, theta_crit=0.7
[39/50] Skipping N=2782559, theta_crit=0.7
[40/50] Skipping N=10000000, theta_crit=0.7
[41/50] Running N= 100, theta_crit=0.9... mean=0.875ms (took 0.0s)
[42/50] Running N= 359, theta_crit=0.9... mean=0.912ms (took 0.0s)
[43/50] Running N= 1291, theta_crit=0.9... mean=1.112ms (took 0.0s)
[44/50] Running N= 4641, theta_crit=0.9... mean=1.980ms (took 0.1s)
[45/50] Running N=16681, theta_crit=0.9... mean=6.333ms (took 0.2s)
[46/50] Running N=59948, theta_crit=0.9... mean=29.576ms (took 0.6s)
[47/50] Running N=215443, theta_crit=0.9... mean=112.777ms (took 2.1s)
[48/50] Running N=774263, theta_crit=0.9... mean=483.404ms (took 8.6s)
[49/50] Skipping N=2782559, theta_crit=0.9
[50/50] Skipping N=10000000, theta_crit=0.9
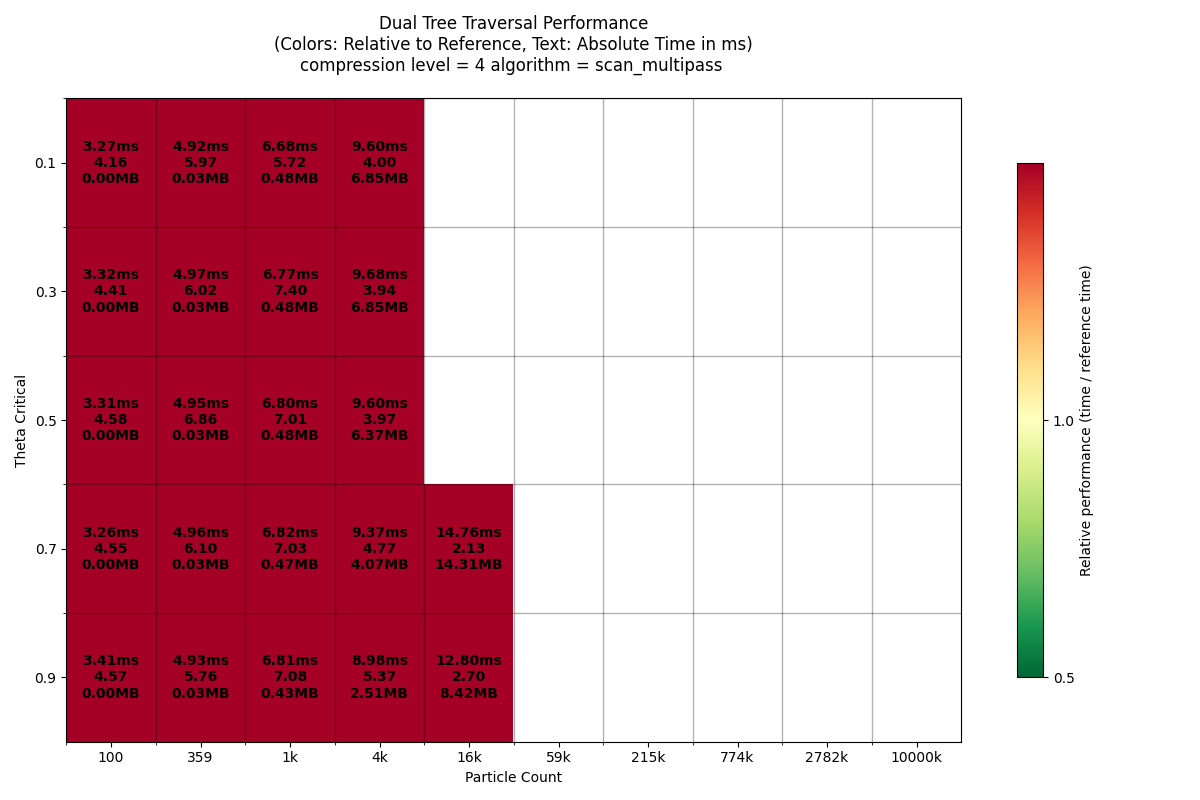
Info: setting dtt implementation to impl : scan_multipass [tree][rank=0]
Running DTT performance benchmarks for scan_multipass ordered=True...
Particle counts: [100, 359, 1291, 4641, 16681, 59948, 215443, 774263, 2782559, 10000000]
Theta_crit values: [0.1, 0.3, 0.5, 0.7, 0.9]
Compression level: 4
[ 1/50] Running N= 100, theta_crit=0.1... mean=4.137ms (took 0.1s)
[ 2/50] Running N= 359, theta_crit=0.1... mean=5.876ms (took 0.1s)
[ 3/50] Running N= 1291, theta_crit=0.1... mean=7.726ms (took 0.1s)
[ 4/50] Running N= 4641, theta_crit=0.1... mean=11.649ms (took 0.2s)
[ 5/50] Skipping N=16681, theta_crit=0.1
[ 6/50] Skipping N=59948, theta_crit=0.1
[ 7/50] Skipping N=215443, theta_crit=0.1
[ 8/50] Skipping N=774263, theta_crit=0.1
[ 9/50] Skipping N=2782559, theta_crit=0.1
[10/50] Skipping N=10000000, theta_crit=0.1
[11/50] Running N= 100, theta_crit=0.3... mean=4.408ms (took 0.1s)
[12/50] Running N= 359, theta_crit=0.3... mean=6.151ms (took 0.1s)
[13/50] Running N= 1291, theta_crit=0.3... mean=8.290ms (took 0.1s)
[14/50] Running N= 4641, theta_crit=0.3... mean=11.105ms (took 0.1s)
[15/50] Running N=16681, theta_crit=0.3... mean=21.355ms (took 0.3s)
[16/50] Skipping N=59948, theta_crit=0.3
[17/50] Skipping N=215443, theta_crit=0.3
[18/50] Skipping N=774263, theta_crit=0.3
[19/50] Skipping N=2782559, theta_crit=0.3
[20/50] Skipping N=10000000, theta_crit=0.3
[21/50] Running N= 100, theta_crit=0.5... mean=4.311ms (took 0.1s)
[22/50] Running N= 359, theta_crit=0.5... mean=6.095ms (took 0.1s)
[23/50] Running N= 1291, theta_crit=0.5... mean=7.891ms (took 0.1s)
[24/50] Running N= 4641, theta_crit=0.5... mean=9.922ms (took 0.1s)
[25/50] Running N=16681, theta_crit=0.5... mean=14.002ms (took 0.2s)
[26/50] Skipping N=59948, theta_crit=0.5
[27/50] Skipping N=215443, theta_crit=0.5
[28/50] Skipping N=774263, theta_crit=0.5
[29/50] Skipping N=2782559, theta_crit=0.5
[30/50] Skipping N=10000000, theta_crit=0.5
[31/50] Running N= 100, theta_crit=0.7... mean=4.356ms (took 0.1s)
[32/50] Running N= 359, theta_crit=0.7... mean=6.014ms (took 0.1s)
[33/50] Running N= 1291, theta_crit=0.7... mean=7.873ms (took 0.1s)
[34/50] Running N= 4641, theta_crit=0.7... mean=9.607ms (took 0.1s)
[35/50] Running N=16681, theta_crit=0.7... mean=12.510ms (took 0.2s)
[36/50] Running N=59948, theta_crit=0.7... mean=20.698ms (took 0.5s)
[37/50] Skipping N=215443, theta_crit=0.7
[38/50] Skipping N=774263, theta_crit=0.7
[39/50] Skipping N=2782559, theta_crit=0.7
[40/50] Skipping N=10000000, theta_crit=0.7
[41/50] Running N= 100, theta_crit=0.9... mean=4.471ms (took 0.1s)
[42/50] Running N= 359, theta_crit=0.9... mean=6.012ms (took 0.1s)
[43/50] Running N= 1291, theta_crit=0.9... mean=7.976ms (took 0.1s)
[44/50] Running N= 4641, theta_crit=0.9... mean=9.820ms (took 0.1s)
[45/50] Running N=16681, theta_crit=0.9... mean=12.025ms (took 0.2s)
[46/50] Running N=59948, theta_crit=0.9... mean=17.407ms (took 0.5s)
[47/50] Skipping N=215443, theta_crit=0.9
[48/50] Skipping N=774263, theta_crit=0.9
[49/50] Skipping N=2782559, theta_crit=0.9
[50/50] Skipping N=10000000, theta_crit=0.9
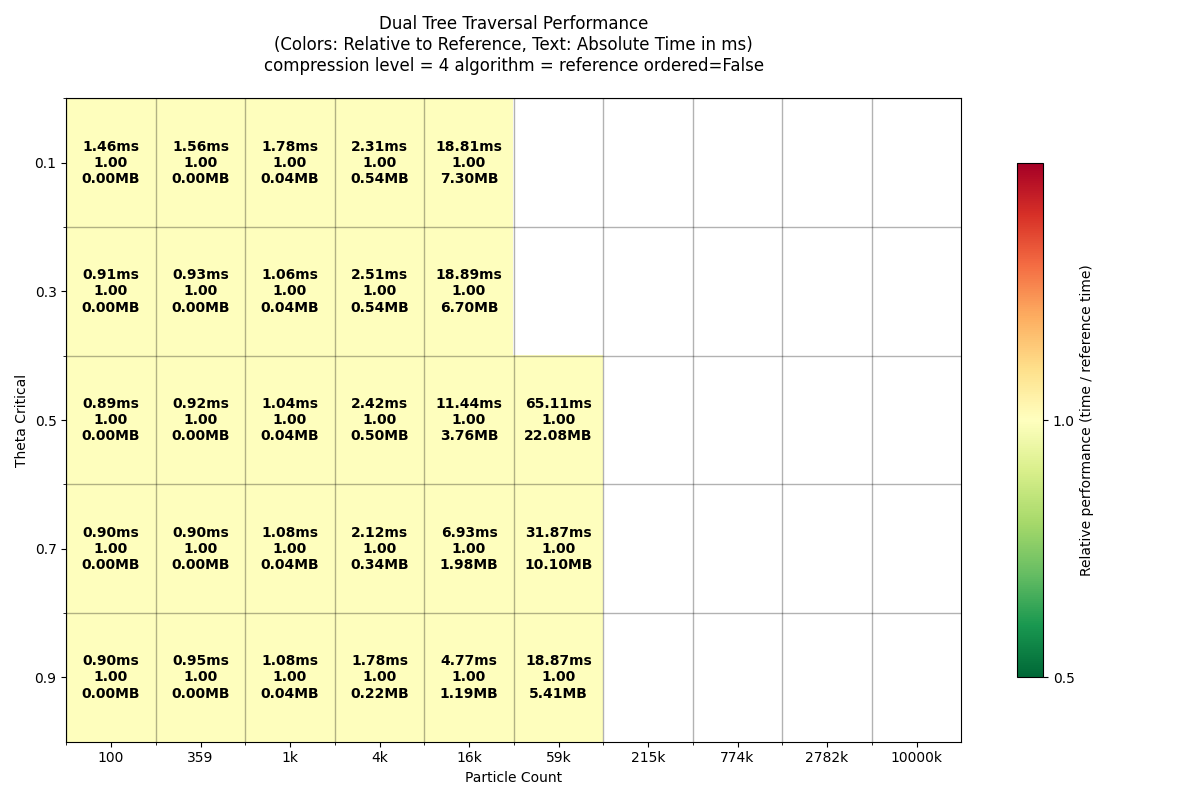
Info: setting dtt implementation to impl : reference [tree][rank=0]
Running DTT performance benchmarks for reference ordered=False...
Particle counts: [100, 359, 1291, 4641, 16681, 59948, 215443, 774263, 2782559, 10000000]
Theta_crit values: [0.1, 0.3, 0.5, 0.7, 0.9]
Compression level: 4
[ 1/50] Running N= 100, theta_crit=0.1... mean=1.271ms (took 0.0s)
[ 2/50] Running N= 359, theta_crit=0.1... mean=1.350ms (took 0.0s)
[ 3/50] Running N= 1291, theta_crit=0.1... mean=1.464ms (took 0.0s)
[ 4/50] Running N= 4641, theta_crit=0.1... mean=2.755ms (took 0.1s)
[ 5/50] Running N=16681, theta_crit=0.1... mean=16.712ms (took 0.3s)
[ 6/50] Skipping N=59948, theta_crit=0.1
[ 7/50] Skipping N=215443, theta_crit=0.1
[ 8/50] Skipping N=774263, theta_crit=0.1
[ 9/50] Skipping N=2782559, theta_crit=0.1
[10/50] Skipping N=10000000, theta_crit=0.1
[11/50] Running N= 100, theta_crit=0.3... mean=0.757ms (took 0.0s)
[12/50] Running N= 359, theta_crit=0.3... mean=0.766ms (took 0.0s)
[13/50] Running N= 1291, theta_crit=0.3... mean=0.916ms (took 0.0s)
[14/50] Running N= 4641, theta_crit=0.3... mean=1.859ms (took 0.1s)
[15/50] Running N=16681, theta_crit=0.3... mean=6.871ms (took 0.2s)
[16/50] Running N=59948, theta_crit=0.3... mean=38.948ms (took 0.7s)
[17/50] Skipping N=215443, theta_crit=0.3
[18/50] Skipping N=774263, theta_crit=0.3
[19/50] Skipping N=2782559, theta_crit=0.3
[20/50] Skipping N=10000000, theta_crit=0.3
[21/50] Running N= 100, theta_crit=0.5... mean=0.774ms (took 0.0s)
[22/50] Running N= 359, theta_crit=0.5... mean=0.854ms (took 0.0s)
[23/50] Running N= 1291, theta_crit=0.5... mean=0.915ms (took 0.0s)
[24/50] Running N= 4641, theta_crit=0.5... mean=1.367ms (took 0.0s)
[25/50] Running N=16681, theta_crit=0.5... mean=2.883ms (took 0.1s)
[26/50] Running N=59948, theta_crit=0.5... mean=11.058ms (took 0.4s)
[27/50] Running N=215443, theta_crit=0.5... mean=35.499ms (took 1.4s)
[28/50] Skipping N=774263, theta_crit=0.5
[29/50] Skipping N=2782559, theta_crit=0.5
[30/50] Skipping N=10000000, theta_crit=0.5
[31/50] Running N= 100, theta_crit=0.7... mean=0.792ms (took 0.0s)
[32/50] Running N= 359, theta_crit=0.7... mean=0.820ms (took 0.0s)
[33/50] Running N= 1291, theta_crit=0.7... mean=0.910ms (took 0.0s)
[34/50] Running N= 4641, theta_crit=0.7... mean=1.129ms (took 0.0s)
[35/50] Running N=16681, theta_crit=0.7... mean=1.998ms (took 0.1s)
[36/50] Running N=59948, theta_crit=0.7... mean=6.159ms (took 0.3s)
[37/50] Running N=215443, theta_crit=0.7... mean=19.455ms (took 1.2s)
[38/50] Running N=774263, theta_crit=0.7... mean=80.199ms (took 4.4s)
[39/50] Skipping N=2782559, theta_crit=0.7
[40/50] Skipping N=10000000, theta_crit=0.7
[41/50] Running N= 100, theta_crit=0.9... mean=0.758ms (took 0.0s)
[42/50] Running N= 359, theta_crit=0.9... mean=0.831ms (took 0.0s)
[43/50] Running N= 1291, theta_crit=0.9... mean=0.833ms (took 0.0s)
[44/50] Running N= 4641, theta_crit=0.9... mean=1.006ms (took 0.0s)
[45/50] Running N=16681, theta_crit=0.9... mean=1.614ms (took 0.1s)
[46/50] Running N=59948, theta_crit=0.9... mean=4.064ms (took 0.3s)
[47/50] Running N=215443, theta_crit=0.9... mean=13.245ms (took 1.1s)
[48/50] Running N=774263, theta_crit=0.9... mean=50.526ms (took 4.3s)
[49/50] Skipping N=2782559, theta_crit=0.9
[50/50] Skipping N=10000000, theta_crit=0.9
Info: setting dtt implementation to impl : parallel_select [tree][rank=0]
Running DTT performance benchmarks for parallel_select ordered=False...
Particle counts: [100, 359, 1291, 4641, 16681, 59948, 215443, 774263, 2782559, 10000000]
Theta_crit values: [0.1, 0.3, 0.5, 0.7, 0.9]
Compression level: 4
[ 1/50] Running N= 100, theta_crit=0.1... mean=0.881ms (took 0.0s)
[ 2/50] Running N= 359, theta_crit=0.1... mean=0.925ms (took 0.0s)
[ 3/50] Running N= 1291, theta_crit=0.1... mean=1.385ms (took 0.0s)
[ 4/50] Running N= 4641, theta_crit=0.1... mean=7.097ms (took 0.1s)
[ 5/50] Running N=16681, theta_crit=0.1... mean=80.955ms (took 0.9s)
[ 6/50] Skipping N=59948, theta_crit=0.1
[ 7/50] Skipping N=215443, theta_crit=0.1
[ 8/50] Skipping N=774263, theta_crit=0.1
[ 9/50] Skipping N=2782559, theta_crit=0.1
[10/50] Skipping N=10000000, theta_crit=0.1
[11/50] Running N= 100, theta_crit=0.3... mean=0.871ms (took 0.0s)
[12/50] Running N= 359, theta_crit=0.3... mean=0.917ms (took 0.0s)
[13/50] Running N= 1291, theta_crit=0.3... mean=1.412ms (took 0.0s)
[14/50] Running N= 4641, theta_crit=0.3... mean=6.247ms (took 0.1s)
[15/50] Running N=16681, theta_crit=0.3... mean=43.627ms (took 0.5s)
[16/50] Running N=59948, theta_crit=0.3... mean=286.094ms (took 3.1s)
[17/50] Skipping N=215443, theta_crit=0.3
[18/50] Skipping N=774263, theta_crit=0.3
[19/50] Skipping N=2782559, theta_crit=0.3
[20/50] Skipping N=10000000, theta_crit=0.3
[21/50] Running N= 100, theta_crit=0.5... mean=0.879ms (took 0.0s)
[22/50] Running N= 359, theta_crit=0.5... mean=0.960ms (took 0.0s)
[23/50] Running N= 1291, theta_crit=0.5... mean=1.355ms (took 0.0s)
[24/50] Running N= 4641, theta_crit=0.5... mean=3.757ms (took 0.1s)
[25/50] Running N=16681, theta_crit=0.5... mean=17.719ms (took 0.3s)
[26/50] Running N=59948, theta_crit=0.5... mean=91.505ms (took 1.2s)
[27/50] Running N=215443, theta_crit=0.5... mean=405.736ms (took 5.1s)
[28/50] Skipping N=774263, theta_crit=0.5
[29/50] Skipping N=2782559, theta_crit=0.5
[30/50] Skipping N=10000000, theta_crit=0.5
[31/50] Running N= 100, theta_crit=0.7... mean=0.914ms (took 0.0s)
[32/50] Running N= 359, theta_crit=0.7... mean=0.918ms (took 0.0s)
[33/50] Running N= 1291, theta_crit=0.7... mean=1.201ms (took 0.0s)
[34/50] Running N= 4641, theta_crit=0.7... mean=2.706ms (took 0.1s)
[35/50] Running N=16681, theta_crit=0.7... mean=11.087ms (took 0.2s)
[36/50] Running N=59948, theta_crit=0.7... mean=53.152ms (took 0.8s)
[37/50] Running N=215443, theta_crit=0.7... mean=237.407ms (took 3.4s)
[38/50] Skipping N=774263, theta_crit=0.7
[39/50] Skipping N=2782559, theta_crit=0.7
[40/50] Skipping N=10000000, theta_crit=0.7
[41/50] Running N= 100, theta_crit=0.9... mean=0.897ms (took 0.0s)
[42/50] Running N= 359, theta_crit=0.9... mean=0.903ms (took 0.0s)
[43/50] Running N= 1291, theta_crit=0.9... mean=1.105ms (took 0.0s)
[44/50] Running N= 4641, theta_crit=0.9... mean=1.986ms (took 0.1s)
[45/50] Running N=16681, theta_crit=0.9... mean=6.081ms (took 0.2s)
[46/50] Running N=59948, theta_crit=0.9... mean=25.992ms (took 0.5s)
[47/50] Running N=215443, theta_crit=0.9... mean=106.967ms (took 2.1s)
[48/50] Running N=774263, theta_crit=0.9... mean=470.360ms (took 8.5s)
[49/50] Skipping N=2782559, theta_crit=0.9
[50/50] Skipping N=10000000, theta_crit=0.9
Info: setting dtt implementation to impl : scan_multipass [tree][rank=0]
Running DTT performance benchmarks for scan_multipass ordered=False...
Particle counts: [100, 359, 1291, 4641, 16681, 59948, 215443, 774263, 2782559, 10000000]
Theta_crit values: [0.1, 0.3, 0.5, 0.7, 0.9]
Compression level: 4
[ 1/50] Running N= 100, theta_crit=0.1... mean=3.105ms (took 0.0s)
[ 2/50] Running N= 359, theta_crit=0.1... mean=4.520ms (took 0.1s)
[ 3/50] Running N= 1291, theta_crit=0.1... mean=6.204ms (took 0.1s)
[ 4/50] Running N= 4641, theta_crit=0.1... mean=8.352ms (took 0.1s)
[ 5/50] Skipping N=16681, theta_crit=0.1
[ 6/50] Skipping N=59948, theta_crit=0.1
[ 7/50] Skipping N=215443, theta_crit=0.1
[ 8/50] Skipping N=774263, theta_crit=0.1
[ 9/50] Skipping N=2782559, theta_crit=0.1
[10/50] Skipping N=10000000, theta_crit=0.1
[11/50] Running N= 100, theta_crit=0.3... mean=3.183ms (took 0.0s)
[12/50] Running N= 359, theta_crit=0.3... mean=4.485ms (took 0.1s)
[13/50] Running N= 1291, theta_crit=0.3... mean=6.023ms (took 0.1s)
[14/50] Running N= 4641, theta_crit=0.3... mean=8.872ms (took 0.1s)
[15/50] Running N=16681, theta_crit=0.3... mean=13.240ms (took 0.2s)
[16/50] Skipping N=59948, theta_crit=0.3
[17/50] Skipping N=215443, theta_crit=0.3
[18/50] Skipping N=774263, theta_crit=0.3
[19/50] Skipping N=2782559, theta_crit=0.3
[20/50] Skipping N=10000000, theta_crit=0.3
[21/50] Running N= 100, theta_crit=0.5... mean=3.065ms (took 0.0s)
[22/50] Running N= 359, theta_crit=0.5... mean=4.371ms (took 0.1s)
[23/50] Running N= 1291, theta_crit=0.5... mean=5.797ms (took 0.1s)
[24/50] Running N= 4641, theta_crit=0.5... mean=7.307ms (took 0.1s)
[25/50] Running N=16681, theta_crit=0.5... mean=10.124ms (took 0.2s)
[26/50] Skipping N=59948, theta_crit=0.5
[27/50] Skipping N=215443, theta_crit=0.5
[28/50] Skipping N=774263, theta_crit=0.5
[29/50] Skipping N=2782559, theta_crit=0.5
[30/50] Skipping N=10000000, theta_crit=0.5
[31/50] Running N= 100, theta_crit=0.7... mean=3.092ms (took 0.0s)
[32/50] Running N= 359, theta_crit=0.7... mean=4.269ms (took 0.1s)
[33/50] Running N= 1291, theta_crit=0.7... mean=5.676ms (took 0.1s)
[34/50] Running N= 4641, theta_crit=0.7... mean=7.239ms (took 0.1s)
[35/50] Running N=16681, theta_crit=0.7... mean=9.734ms (took 0.2s)
[36/50] Running N=59948, theta_crit=0.7... mean=14.910ms (took 0.4s)
[37/50] Skipping N=215443, theta_crit=0.7
[38/50] Skipping N=774263, theta_crit=0.7
[39/50] Skipping N=2782559, theta_crit=0.7
[40/50] Skipping N=10000000, theta_crit=0.7
[41/50] Running N= 100, theta_crit=0.9... mean=4.639ms (took 0.1s)
[42/50] Running N= 359, theta_crit=0.9... mean=5.774ms (took 0.1s)
[43/50] Running N= 1291, theta_crit=0.9... mean=6.127ms (took 0.1s)
[44/50] Running N= 4641, theta_crit=0.9... mean=7.547ms (took 0.1s)
[45/50] Running N=16681, theta_crit=0.9... mean=9.418ms (took 0.2s)
[46/50] Running N=59948, theta_crit=0.9... mean=13.038ms (took 0.4s)
[47/50] Skipping N=215443, theta_crit=0.9
[48/50] Skipping N=774263, theta_crit=0.9
[49/50] Skipping N=2782559, theta_crit=0.9
[50/50] Skipping N=10000000, theta_crit=0.9
Plot the performance benchmarks for all implementations
282 dump_folder = "_to_trash"
283
284 import os
285
286 # Create the dump directory if it does not exist
287 if shamrock.sys.world_rank() == 0:
288 os.makedirs(dump_folder, exist_ok=True)
289
290 ref_key = "reference ordered=False"
291 largest_refalg_value = np.nanmax(results[ref_key]["results_min"])
292
293 i = 0
294 # iterate over the results
295 for k, v in results.items():
296 # Get the results for this algorithm
297 particle_counts = v["particle_counts"]
298 theta_crits = v["theta_crits"]
299 results_min = v["results_min"]
300 results_max_mem_delta = v["results_max_mem_delta"]
301
302 # Get reference algorithm results for comparison
303 reference_min = results[ref_key]["results_min"]
304
305 # Create and display the plot
306 fig, ax = create_checkerboard_plot(
307 particle_counts,
308 theta_crits,
309 results_min,
310 compression_level,
311 v["name"],
312 largest_refalg_value,
313 reference_min,
314 results_max_mem_delta,
315 )
316
317 plt.savefig(f"{dump_folder}/benchmark-dtt-performance-{i}.pdf")
318 i += 1
319
320 plt.show()
Total running time of the script: (1 minutes 32.720 seconds)
Estimated memory usage: 293 MB